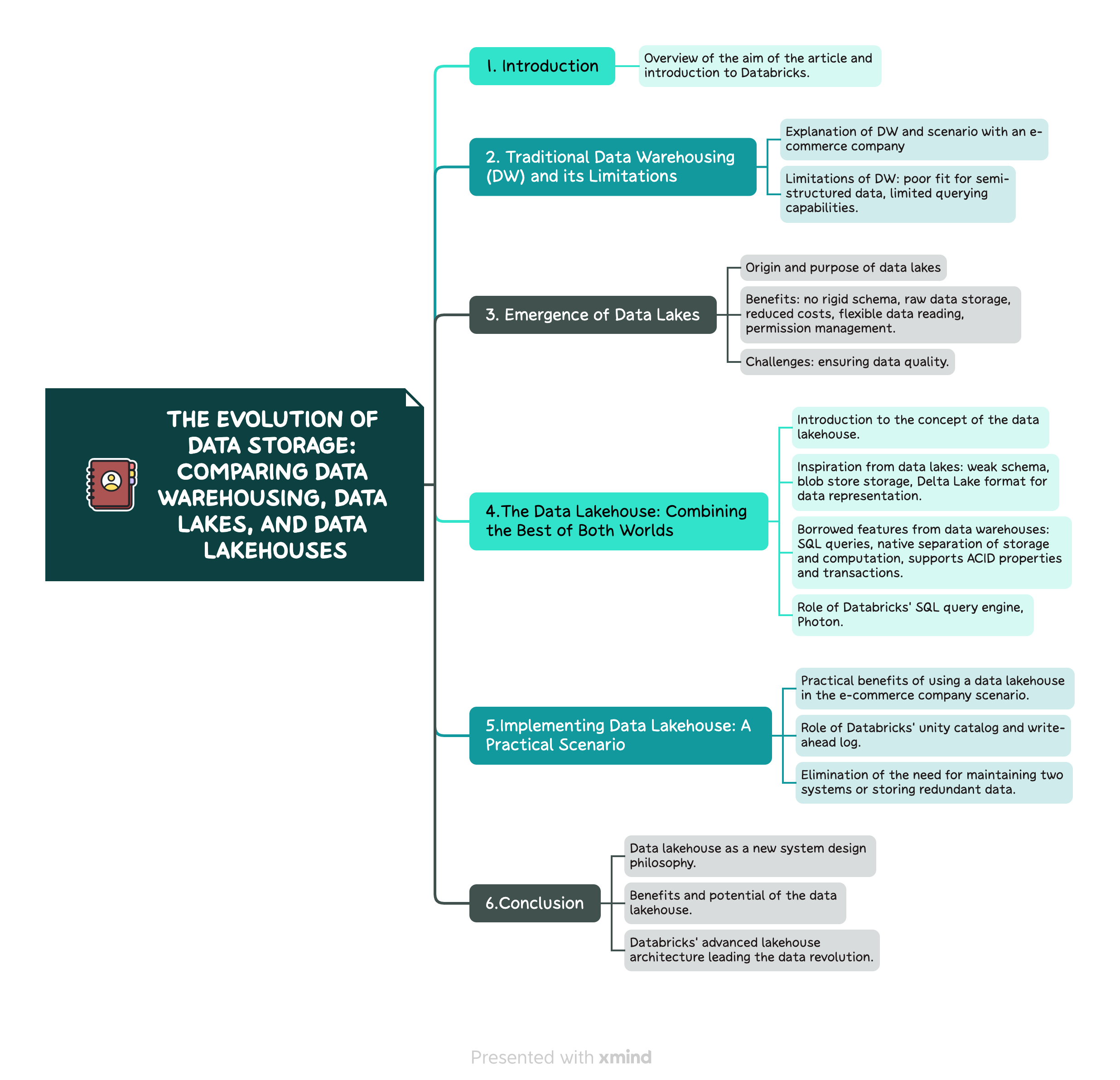
 Mind map of this article
Mind map of this article
Introduction
This article is inspired by a post written by a Databricks engineer. It is aimed at company engineers who use the Databricks ecosystem but are unclear about why they chose it or its advantages. With this piece, we hope to demystify the underlying concepts and benefits of Databricks, specifically in comparison to Data Warehouses and Data Lakes.
Traditional Data Warehousing and its Limitations
Let’s begin with a scenario where an e-commerce company needs to record user activity data, particularly details of items purchased by the user. This data, semi-structured by nature, is a poor fit for traditional data warehouses (DW). The data will look like this:

The structure of this data resembles a list of varying lengths, containing items and their details. As traditional DWs model data in a strictly tabular format, this necessitates the creation of a new column, for instance, ‘purchased_items’, to capture the list of items. However, machine learning data tends to follow a tree-like structure, and storing it in a relational database can result in data loss.
Moreover, the querying capabilities of traditional DWs are somewhat limited. For instance, running a query to find out how many users bought items totaling over 50 units could be a difficult task, whereas it’s straightforward in a data lakehouse.
The emergence of Data Lakes
Despite the dominant role of relational databases, numerous NoSQL tools have emerged over the years. Data lakes are one such solution, born from the necessity to handle non-traditional data structures. They store and manage all company data in raw form before integrating them into the data warehouse.
Unlike Data Warehouses, Data Lakes do not require a rigid schema. The data, which can be semi-structured or non-structured, is essentially stored in simple formats (like Apache Parquet) on a blob store. While this significantly reduces costs and allows flexible data reading and permission management, it also poses challenges like ensuring data quality.
As data warehouses evolve into data lakes, let’s look at how the previous scenario changes:
Returning to the e-commerce company example, let’s see how data lakes address the pain points of data warehouses. As mentioned, a new table was created in the data warehouse to store user activity information for data scientists to analyze. Suppose we need to develop a machine learning model to predict the probability of a user buying a product. It’s clearly a binary classification model, with each training data piece containing information about a user and a product.
Typically, an ETL pipeline is added behind the message queue to clean data into this format and store it on S3, providing input for the ML model training system. If our situation becomes more complex, with different ML teams needing to perform ML modeling on different user activity data, we generally have one ETL pipeline responsible for generating user activity data and storing it on S3. Another pipeline is responsible for generating item data and storing it on S3. Each ML team manages its specific ETL pipeline according to its business needs, joining user activity data and item data to generate its desired model training data. The data stored on S3, combined with various ETL pipelines, essentially form a data lake.
The Data Lakehouse: Combining the Best of Both Worlds
In the evolving data landscape, a new concept, the data lakehouse, is gaining traction. The data lakehouse combines the flexibility of data lakes with the reliability and performance of data warehouses.
The data lakehouse doesn’t need a strong schema and just exists on a blob store, taking inspiration from the data lake. Databricks’ data lakehouse is based on the Delta Lake format, a tree-like structure for data representation, which is inherently suitable for machine learning.
Borrowing from data warehouses, the data lakehouse supports SQL queries, which are executed by Databricks’ own SQL query engine, Photon. The engine is specially designed to work with data formats with a weak schema, like the Delta Lake format, requiring extensive optimization to match the performance of data warehouses.
Another advantage of the data lakehouse is the native separation of storage and computation, providing flexibility and scalability. Finally, to maintain the benefits of traditional databases, Databricks’ data lakehouse supports ACID properties and transactions, thanks to a write-ahead log implemented for the Delta Lake format.
Implementing Data Lakehouse: A Practical Scenario
To illustrate the practical benefits of using a data lakehouse, let’s revisit our e-commerce company example. With Databricks’ lakehouse, the company only needs to maintain one user activity table. This table can house all user activity data and can be directly queried using SQL by data scientists for analysis. Simultaneously, machine learning teams can use ETL pipelines to extract and clean the data, generating new tables for machine learning.
Thanks to Databricks’ unity catalog and write-ahead log, we can manage permissions and data lineage conveniently. Thus, by adopting Databricks’ lakehouse architecture, we no longer need to maintain two systems or store redundant data across a data lake and warehouse.
Conclusion
Data lakehouses are not a new technology, but rather a new system design philosophy. By using an open-source data storage format that inherently suits machine learning, and further implementing features traditionally associated with data warehouses, data lakehouses offer the best of both worlds.
Through this innovative combination of characteristics, the data lakehouse is well-positioned to address the modern challenges of big data, providing an efficient, flexible, and scalable solution for data storage and management. Databricks, with its advanced lakehouse architecture, is at the forefront of this data revolution.
Reference
https://www.1point3acres.com/bbs/thread-851795-1-1.html
Dabbèchi, H., Haddar, N.Z., Elghazel, H., Haddar, K. (2021). Social Media Data Integration: From Data Lake to NoSQL Data Warehouse. In: Abraham, A., Piuri, V., Gandhi, N., Siarry, P., Kaklauskas, A., Madureira, A. (eds) Intelligent Systems Design and Applications. ISDA 2020. Advances in Intelligent Systems and Computing, vol 1351. Springer, Cham. https://doi.org/10.1007/978-3-030-71187-0_64