Goal:
Use TPUs to identify toxicity comments across multiple languages.
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import tensorflow as tf
from keras.models import Sequential
from keras.layers.recurrent import LSTM, GRU, SimpleRNN
from keras.layers.core import Dense,Activation,Dropout
from keras.layers.embeddings import Embedding
from keras.layers.normalization import BatchNormalization
from keras.utils import np_utils
from sklearn import preprocessing,decomposition,model_selection,metrics,pipeline
from keras.layers import GlobalMaxPooling1D,Conv1D,MaxPooling1D,Flatten,Bidirectional,SpatialDropout1D
from keras.preprocessing import sequence,text
from keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from plotly import graph_objs as go
import plotly.express as px
import plotly.figure_factory as ff
Environment Configuration
Utilize TPUs for distribution strategies
#Detect hardware, return appropriate distribution strategy
try:
#TPU detection. No parameters necessary if TPU_NAME environment variable is
#set: this is always the case in Kaggle
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
print('Running on TPU',tpu.master())
except ValueError:
tpu = None
if tpu:
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.get_strategy()
else:
#Default distribution strategy in Tensorflow.works on CPU and single GPU
strategy = tf.distribute.get_strategy()
print("REPLICAS: ", strategy.num_replicas_in_sync)
train = pd.read_csv('./toxic-comment-train.csv')
validation = pd.read_csv('./validation.csv')
test = pd.read_csv('./test.csv')
#Feature Engineering
train.drop(['severe_toxic','obscene','threat','insult','identity_hate'],axis = 1,inplace=True)
train = train.loc[:12000,:]
train.shape
(12001, 3)
1.check the maximum number of words that can be present in a comment, this will help later in padding
train['comment_text'].apply(lambda x:len(str(x).split())).max()
1403
def roc_auc(predictions,target):
'''
This method returns the AUC Score when given the Predictions and Labels
'''
fpr,tpr, thresholds= metrics.roc_curve(target,predictions)
roc_auc = metrics.auc(fpr,tpr)
return roc_auc
#Data Preparation
xtrain,xvalid,ytrain,yvalid = train_test_split(train.comment_text.values, train.toxic.values,
stratify = train.toxic.values,
random_state = 42,
test_size = 0.2,
shuffle = True)
1.Simple RNN
Recurrent Neural Network(RNN) is a type of Neural Network where the output from previous step are fed as input to the current step.
Tokenizer
#using keras tokenizer here
token = text.Tokenizer(num_words = None)
max_len = 1500
token.fit_on_texts(list(xtrain)+list(xvalid))
xtrain_seq = token.texts_to_sequences(xtrain)
xvalid_seq = token.texts_to_sequences(xvalid)
Padding
#zero pad the sequences
xtrain_pad = sequence.pad_sequences(xtrain_seq,maxlen=max_len)
xvalid_pad = sequence.pad_sequences(xvalid_seq,maxlen=max_len)
word_index = token.word_index
Simple RNN - Training
%%time
with strategy.scope():
#A simpleRNN without any pretrained embeddings and one dense layer
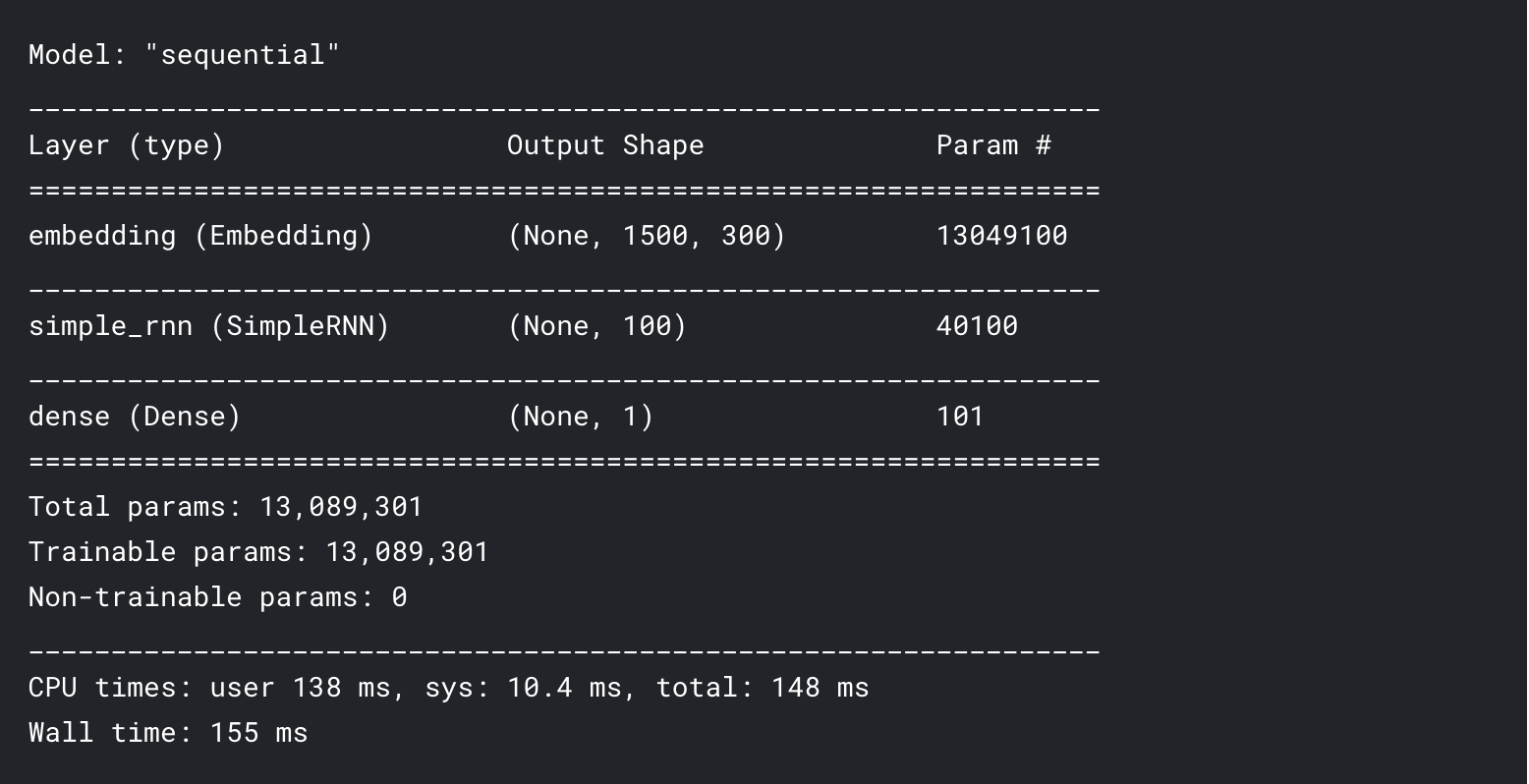
model = Sequential()
model.add(Embedding(len(word_index)+1,300,input_length = max_len))
model.add(SimpleRNN(100))
model.add(Dense(1,activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',optimizer='adam',metrics = ['accuracy'])
model.summary()
Simple RNN - Fitting,Predicting, Evaluating
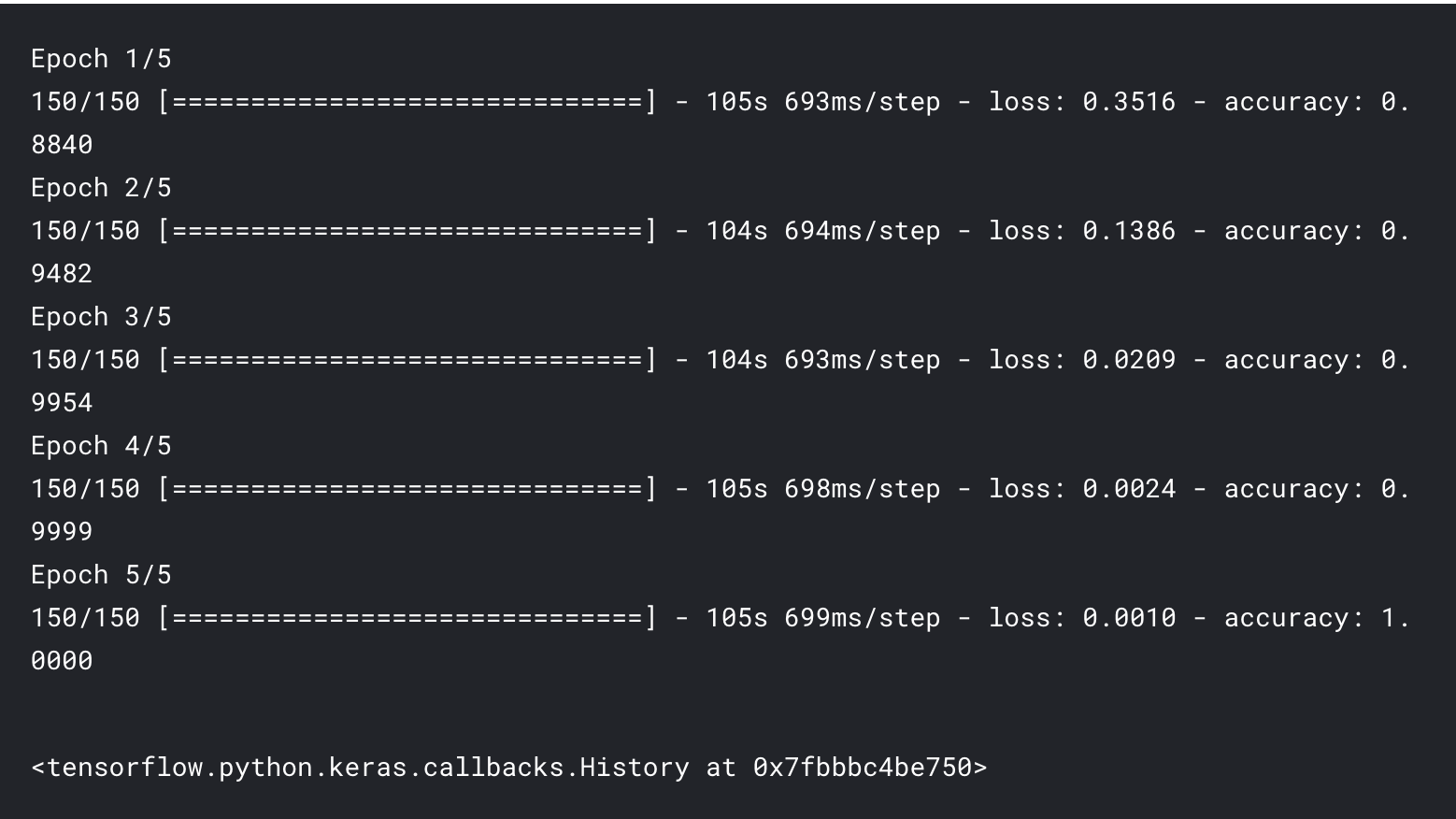
model.fit(xtrain_pad, ytrain,epochs = 5, batch_size = 64*strategy.num_replicas_in_sync)
scores = model.predict(xvalid_pad)
print("Auc:%.2f" % (roc_auc(scores,yvalid)))
Auc:0.82
scores_model = []
scores_model.append({'Model':'SimpleRNN','AUC_Score':roc_auc(scores,yvalid)})
[{‘Model’: ‘SimpleRNN’, ‘AUC_Score’: 0.8221208596590057}]
scores_model
Embedding
Utilize Glove
embeddings_index = {}
f = open('./glove.840B.300d.txt','r',encoding = 'utf-8')
for line in tqdm(f):
values = line.split(' ')
word = values[0]
coefs = np.array([float(val) for val in values[1:]])
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
2196018it [05:18, 6895.53it/s] Found 2196017 word vectors.
2. LSTM
LSTM - Training
embedding_matrix = np.zeros((len(word_index)+1,300))
for word,i in tqdm(word_index.items()):
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
100%|██████████| 43496/43496 [00:00<00:00, 196129.82it/s]
%%time
with strategy.scope():
#a simple LSTM with glove embeddings and one dense layer
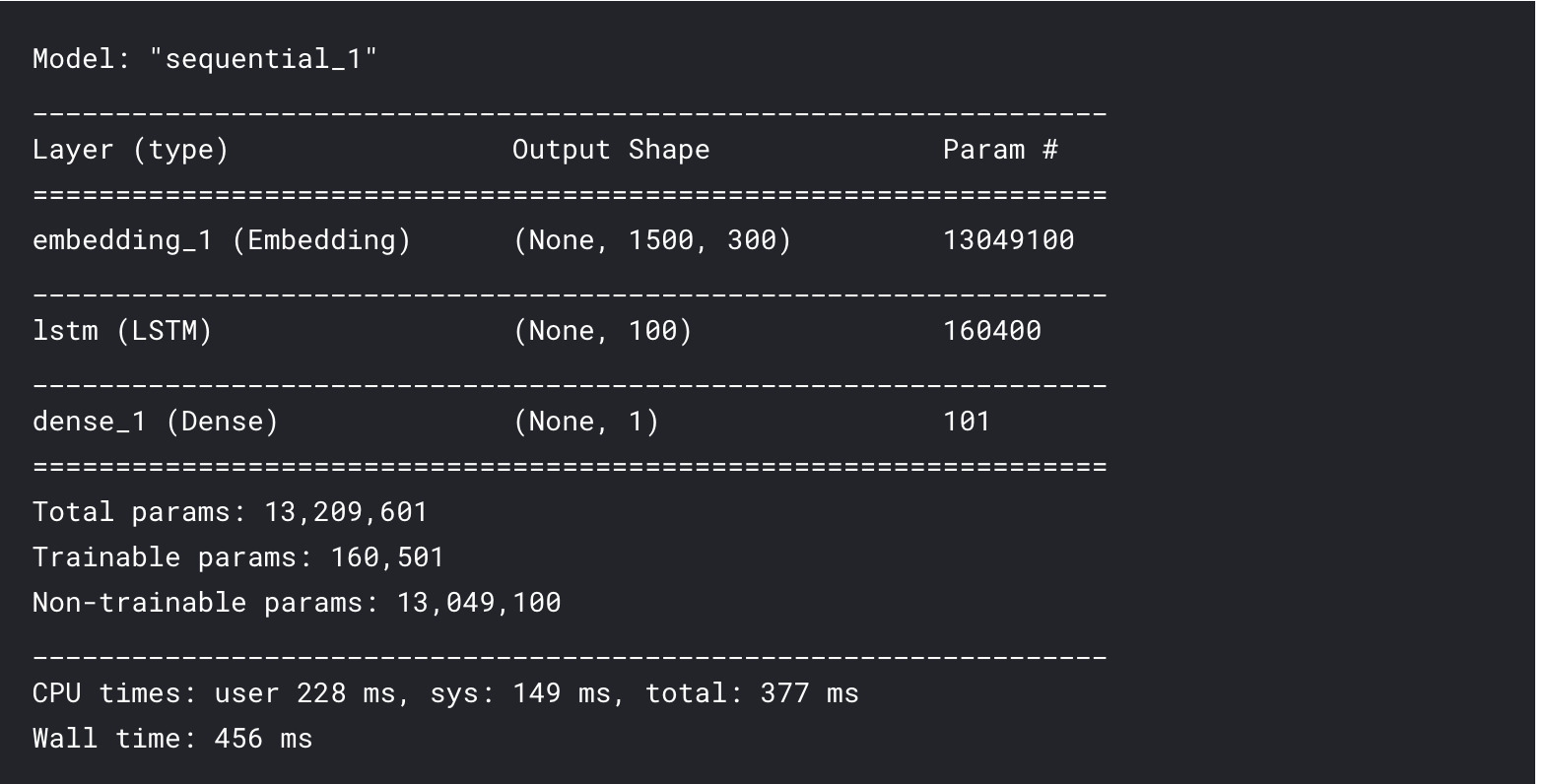
model = Sequential()
model.add(Embedding(len(word_index)+1,
300,
weights = [embedding_matrix],
input_length = max_len,
trainable = False))
model.add(LSTM(100,dropout = 0.3,recurrent_dropout = 0.3))
model.add(Dense(1,activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',optimizer = 'adam',metrics = ['accuracy'])
model.summary()
LSTM - Fitting,Predicting, Evaluating
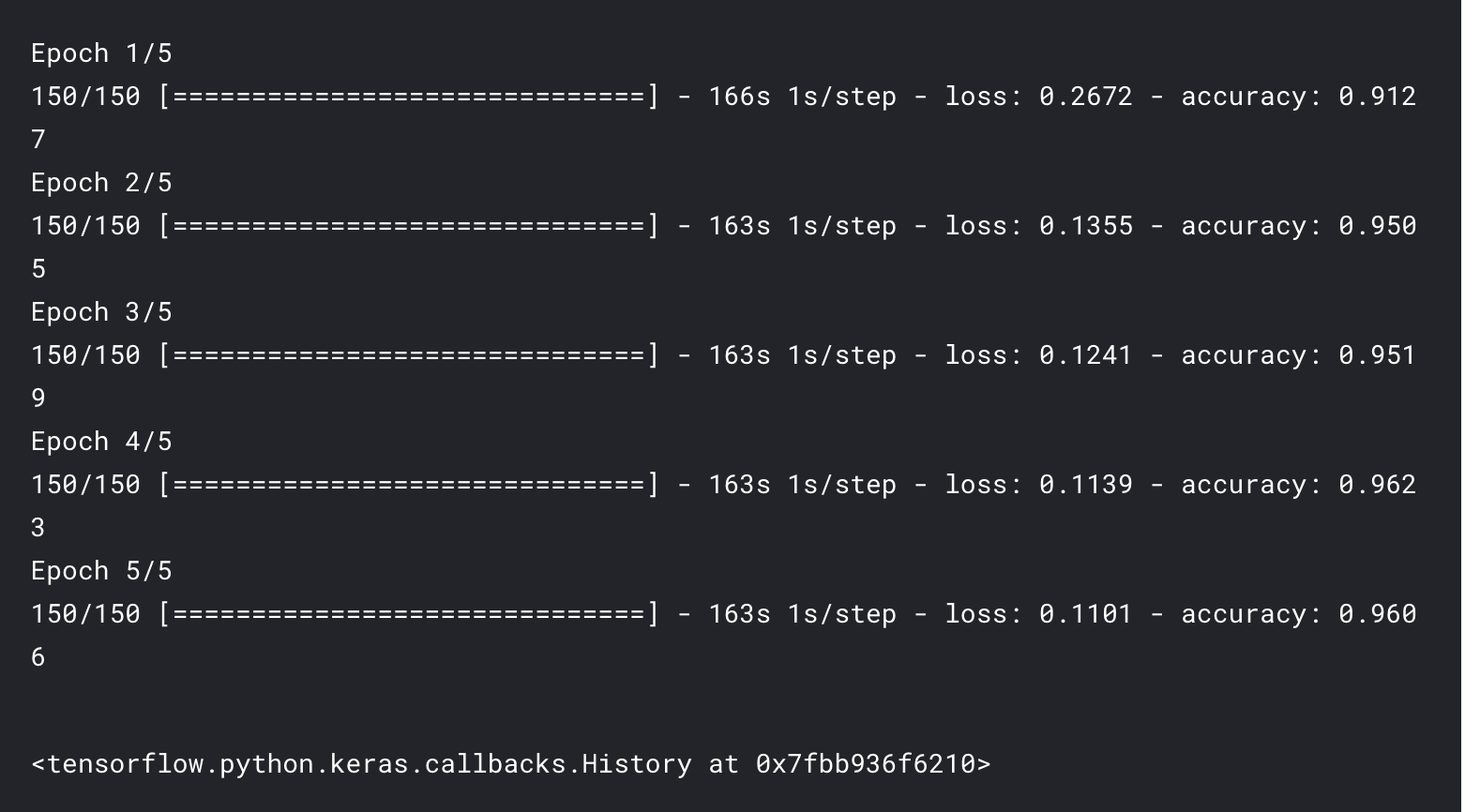
model.fit(xtrain_pad,ytrain,epochs = 5,batch_size = 64*strategy.num_replicas_in_sync)
scores = model.predict(xvalid_pad)
print("Auc:%.2f" % (roc_auc(scores,yvalid)))
Auc:0.97
scores_model.append({'Model':'LSTM','AUC_Score':roc_auc(scores,yvalid)})
3. GRU (Gated Recurrent Unit)
GRU - Training
%%time
with strategy.scope():
# GRU with glove embedding and two dense layers
model = Sequential()
model.add(Embedding(len(word_index)+1,
300,
weights = [embedding_matrix],
input_length = max_len,
trainable = False))
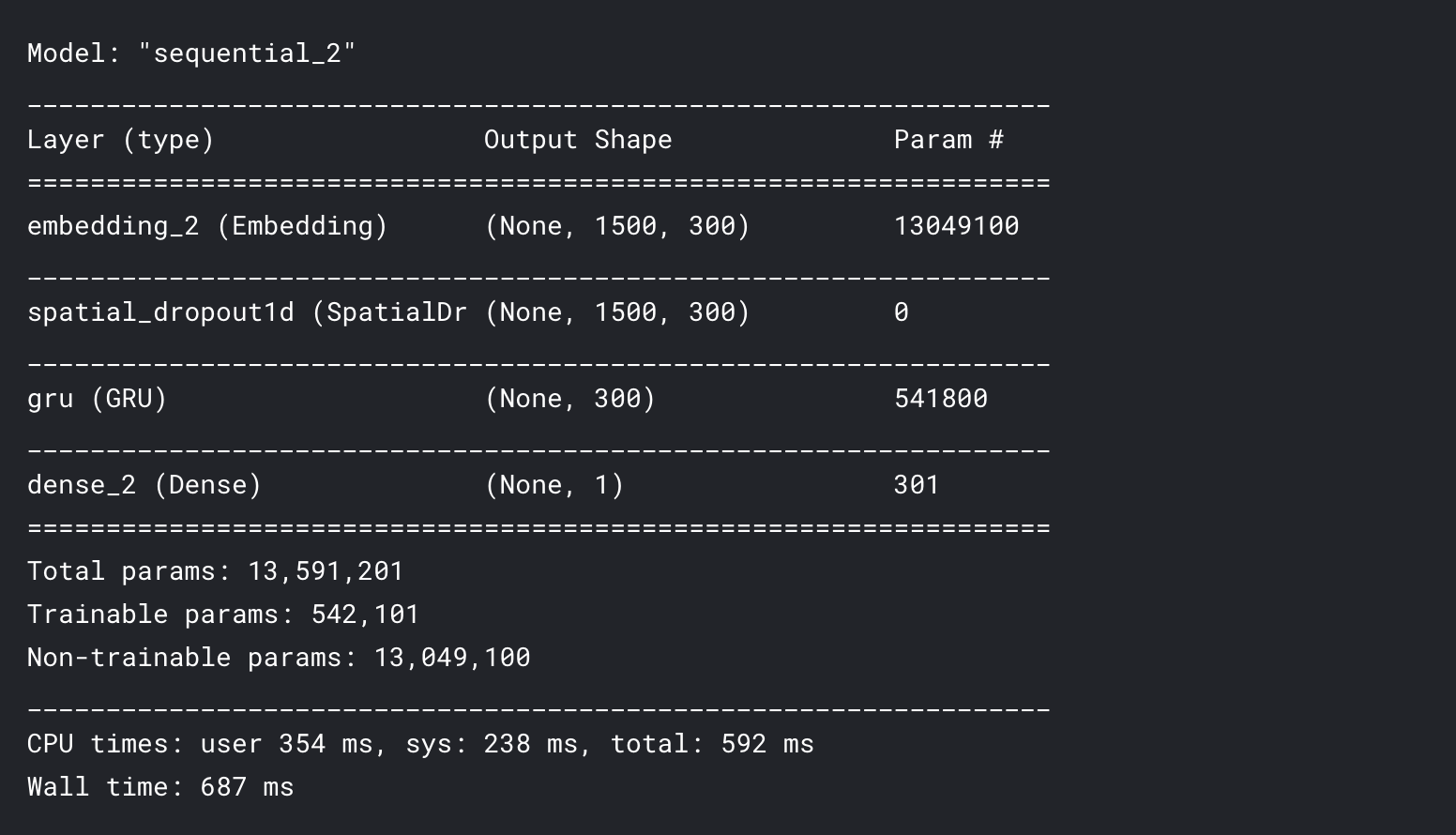
model.add(SpatialDropout1D(0.3))
model.add(GRU(300))
model.add(Dense(1,activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',optimizer = 'adam', metrics = ['accuracy'])
model.summary()
GRU - Fitting,Predicting, Evaluating
model.fit(xtrain_pad,ytrain,epochs = 5, batch_size = 64*strategy.num_replicas_in_sync)
scores = model.predict(xvalid_pad)
print("Auc: %.2f" % (roc_auc(scores,yvalid)))
scores_model.append({'Model':'GRU','AUC_Score':roc_auc(scores,yvalid)})
[{‘Model’: ‘SimpleRNN’, ‘AUC_Score’: 0.8221208596590057}, {‘Model’: ‘LSTM’, ‘AUC_Score’: 0.9695095015582637}, {‘Model’: ‘GRU’, ‘AUC_Score’: 0.9761518790349707}]
4.Bi-Directional RNN
Bi-Directional RNN - Training
%%time
with strategy.scope():
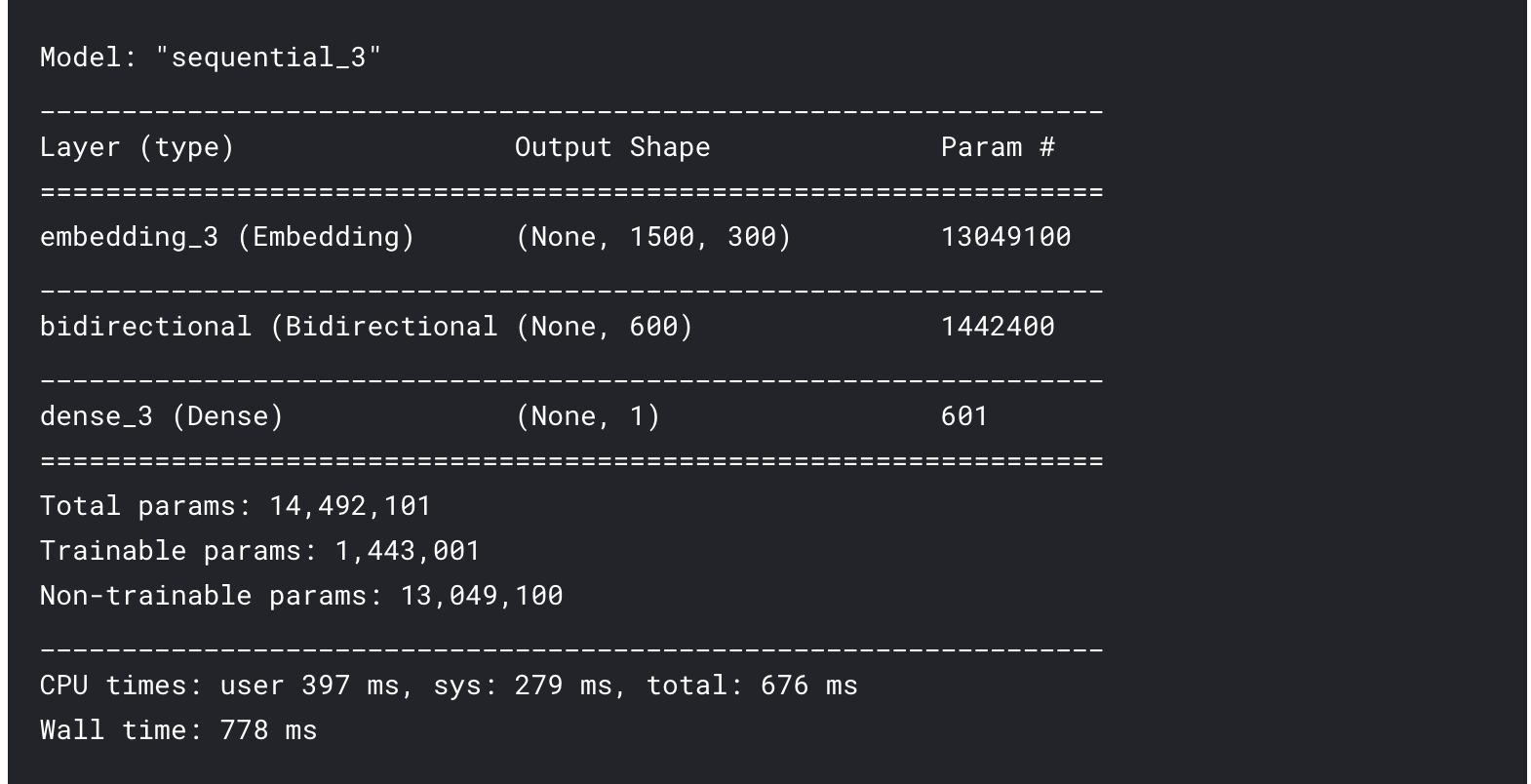
model = Sequential()
model.add(Embedding(len(word_index)+1,
300,
weights = [embedding_matrix],
input_length = max_len,
trainable = False))
model.add(Bidirectional(LSTM(300,dropout = 0.3,recurrent_dropout = 0.3)))
model.add(Dense(1,activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',optimizer = 'adam',metrics = ['accuracy'])
model.summary()
Bi-Directional RNN- Fitting,Predicting, Evaluating
model.fit(xtrain_pad, ytrain, nb_epoch=5, batch_size=64*strategy.num_replicas_in_sync)
scores = model.predict(xvalid_pad)
print("Auc: %.2f" % (roc_auc(scores,yvalid)))
scores_model.append({'Model':'LSTM','AUC_Score':roc_auc(scores,yvalid)})
Results
results = pd.DataFramerame(scores_model).sort_values(by = 'AUC_Score',ascending = False)
results.style.background_gradient(cmap = 'Blues')